However, not everyone need to dig into the source code, normally more people will just call the Hadoop APIs to write a MapReduce program. When you write a MapReduce program, you rarely get it right for one time, then you need to debug your code.
This time I’ll show you how to debug your Hadoop applications using the IntelliJ IDE.
Environment: CentOS 6.6, Oracle JDK 1.7.0_75, Maven 3.2.5, IntelliJ Idea 14.0.3
1. Create a MapReduce Maven project
First we need to create a MapReduce program to debug. Let’s use the simplest example, WordCount, for demonstration. The source code is here WordCount – Hadoop Wiki.
1.1 Generate the Maven project
Use the mvn command to generate the scaffolding for the project.
mvn archetype:generate -DgroupId=me.soulmachine -DartifactId=wordcount -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Delete the src/test/java/me/soulmachine/AppTest.java file, as it will not be used in this example, and rename the src/main/java/me/soulmachine/App.java file to WordCount.java.
Now the structure of the project is as the following:
tree ./wordcount
wordcount/
├── pom.xml
└── src
├── main
│ └── java
│ └── me
│ └── soulmachine
│ └── WordCount.java
└── test
└── java
└── me
└── soulmachine
1.2 Write the code
Rename the src/main/java/me/soulmachine/App.java file to WordCount.java, edit the file and copy and paste the code from WordCount – Hadoop Wiki, remember to change the first line from package org.myorg to package me.soulmachine.
I made some improvements to this code, check it out:
1.3 Edit the pom.xml file
The content of the pom.xml file is as the following:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>me.soulmachine</groupId>
<artifactId>wordcount</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>wordcount</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.6.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>me.soulmachine.WordCount</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
1.4 Compile
mvn clean package
If this step succeeds, move to the next step.
2. Debug WordCount in IntelliJ Idea
2.1 Open the project in IntelliJ Idea
Launch IntelliJ Idea, click File->Open and open the pom.xml, thus you can import the project into IntelliJ Idea.
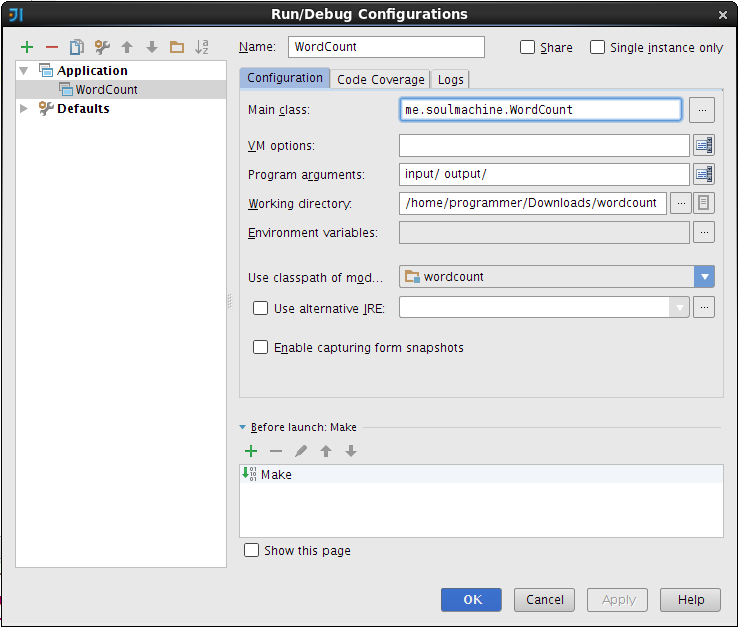
2.2 Create a Run/Debug Configuration
Select the project “WordCount”, Click menu Run->Edit Configurations ...,
- Click the button on the right of
Main Classand selectme.soulmachine.WordCountas the main class. - Set
Program Argumentstoinput/ output, and create a directory namedinputin the project directory, no need to create theoutput/directory - Leave other fields as default.
- Click
OKand finish.
2.3 Run the program
- Create a text file named
file1.txtin theinput/directory and set its content asHello World Bye World, create another text file namedfile2.txtand set its content toHello Hadoop Goodbye Hadoop. - Click menu
Run->Run 'Word Count', after it finishes, you will see a fold namedoutput/in the project root directory and there are two files namedpart-r-00000and_SUCCESS.
2.4 Debug the program
Set a break point in the main function and click menu Run->Debug 'Word Count', then you can debug the code step by step.